久しぶりにマサカリが飛んでくるネタらしい。
ネットショップを20年近くやってると、うちみたいな弱小零細でも何万何十万と住所処理を処理することになり言わずには居られない鬱憤もたまる。
つくづく日本語のシステム、データベース化は難しい。
英語であればアルファベット24文字と大文字小文字ぐらいなのでUpper()なりlower()なりでどちらかに統一すれば検索できる。
日本語は漢字、ひらがな、カタカナぐらい?
漢字は一般的なコンピューターシステムでサポートされているJIS系の第1~4に補助漢字までいれてだいたい約16,000字ぐらいが一般的なフォントで対応されている。
ということは、24文字を1万6千文字に増やした分だけ頑張らなきゃいけないのか! それは大変だね!!
・・・なんていう枠には収まらない。
だからこそ、地獄のフタを一度でも開けた人たちはマサカリを投げつけるのである。完全に理解した曲線のバカ山の能天気さは絶望の谷底からみると眩しすぎるのだ。
地獄に落ちてしまった亡者が手をのばすほどには。
16000文字÷24文字=666.66666666666倍
そこは決して開けてはいけない地獄のフタなのである。
分かち書きカカシ先生は脳みそを求めて旅に出る地獄
ちょいと前に話題になった動画に「変なAI」というのがあった。
雨穴さんの【科学ホラーミステリー】変なAI
https://www.youtube.com/watch?v=NAv0aScEQm0
このホラーミステリー的な動画では作中にAI「kakashi」というのが出てくる。カカシと聞くと、インターネット老人会の人たちはすこしざわざわする。
古い話し。
kakashi、実は2000年の頃に実在していて、かつては全文検索エンジンをつくるのに、kakashiやらnamazuやらをつかって分かち書き、インデックス化をしている時代があった。
分かち書きというのは、英語の場合は単語と単語の間がスペースで区切られているため、単語で検索することができるが、「日本語 は 文中 に 区切り が ない」ので、こんな感じ分解してやる。
チャセンやらメカブやら形態素解析が一般化する前までは突っ込まれたテキストをどこで区切るのかは実に大問題で、無計画な全探索などをおこなってしまうと一生かけても応答しないぐずのろ検索エンジンになってしまうのだ。そんな風に予め持っている手持ちの辞書と突き合わせて文章を細切れにして索引をつけておく必要があった。
愛知海部飛島新田竹之郷ヨタレ南ノ割
これは日本一長い住所から、あえて郡とか字の区切り文字表記を抜いたものであるが、日本人の何人がこれを正確に分かち書くことができるだろうか?線でも引いて区切ってみてほしい。
正解はこれ。
愛知県 海部郡 飛島村 大字飛島新田 字竹之郷 ヨタレ南ノ割
人間に難しいことはAIにも難しい。
2023年現在、だいぶ進化したとは言え、ChatGPTに日本語の文字数を尋ねるとおかしな答えが帰ってくることがある。夏を季語に俳句を読んでもらった。

2023年なうてのAI、ChatGPTさんは俳句を読めても、それが何文字ですか?みたいな人間には簡単に見える質問には満足に答えることができないことがある。ここに日本語の難しさがある。
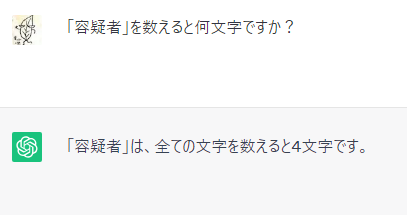
もしかしたらこれは、GPTの学習が「日本語」ではなく、文字コードのバイナリで線形学習していることによる弊害かもしれない。存在しない「視覴」なる単語を使いだしたという騒動を見ているとその確信を強くするが、マルチモーダルを目指す過程に今この瞬間だけ見ることができるマルチバイト言語に現れた時代の徒花と考えれば、音数え 趣深し 梅雨の藍。
これはおもしろい。UTF-8とChatGPTのトークン:
視覴 e8 a6 96 e8 a6 b4 |25038|244|25038|112|
視覚 e8 a6 96 e8 a6 9a |25038|244|25038|248|
視聴 e8 a6 96 e8 81 b4 |25038|244|36735|112|
「覚」の前半と「聴」の後半がくっついたみたい https://t.co/oSpUfNxsUN— Haruhiko Okumura (@h_okumura) June 8, 2023
ちょっとだけ解説すると、文字コードのUTF-8のバイナリはリバースにスタックされてるので日本語化するときは読み込み順を逆にしてからエンコードしてやらにゃならない。U+07FFみたいなんがバイナリ読み込みするとFF07みたいに拾われてくるので07FFに結合してUTF-8でデコードする感じ。これはUTF-8が1-4バイトの可変長であることに多分由来しているんだろうけど詳しくは知らんし自分には荷が重いので、ここではそんな地獄もあるよと軽く触れる程度で終える。しらんけど。
地名の読み方無限地獄
日本語を分かち書くことはただでさえ難しいのに、さらに厄介なことに、固有名詞、地名はさらに輪をかけてそれを困難にする。
地名をなんと読むか、読めない地名をどこで区切るかは母語を日本語にする人にもとても難しい問題だ。
そのため表現も揺らぎやすい。
やがて同じ読みでもいくつも書き方が存在するようになる。
山手、山の手、山ノ手。
ひとつの書き方にいくつも読み方、ひとつの読み方に複数の書き方が存在するようになる。
山手と書いて、やまのてと読んだり、やまてと読んだり、どちらでも正解だったり、読み方が決まっていたり、あるいはどちらとも間違いだったりする。会社によって自治体によって運送会社によって正解が変わる。東京にも山の手はあるし神奈川にも神戸にもある。
これに方言も混じれば読み方がさらに増え、さらに書き方が増える。
こんな風にして地名は発散する。
昨年ニホンゴムズイという、アプリを習作がてら作った。
歴史的な経緯(?)から千葉県にはとてもむずかしい難読地名が多いのだけど、それを4択クイズにしただけのそんなにおもしろくもないゲームだ。
※ 今はAppleデベロッパライセンス切れ(?)でダウンロードできないけど、一応リンクだけ残しておく
https://apps.apple.com/jp/app/%E3%83%8B%E3%83%9B%E3%83%B3%E3%82%B4%E3%83%A0%E3%82%BA%E3%82%A4/id1608182925
我孫子市、富津市、酒々井町、東庄町
匝瑳市、鋸南町、八街市
読めるだろうか?
正解は・・・
↓
我孫子市(あびこし)、富津市(ふっつし)、酒々井町(しすいまち)、東庄町(とうのしょうまち)、匝瑳市(そうさし)、鋸南町(きょなんまち)、八街市(やちまたし)
千葉県の基礎自治体だけをあげつらっても、ごらんの難読さ加減。
ちなみ、今ちらっとゲームのデータを見てきたのだけど、千葉県では地名に使われる漢字は常用漢字うち737文字しか使われておらず、1538が不使用となっている。逆に139文字は常用漢字以外の漢字が使われていた。
同表記なのに別の場所という例もある。
181-0016 東京都三鷹市深大寺と182-0012 東京都調布市深大寺は数キロと絶妙に離れているが連続した一体エリアではない。
調布深大寺にある植物公園は神代寺植物公園だの神代高校だの、神代とする別の漢字表記もある。
深大寺がお寺の名前に由来しいて、神代は神代村に由来しているわけだが、こんな風にすこしの区別付けのために漢字表記をあえて変えた。そしてその変更にはそれなりのこだわりがあったので放棄するわけにはいかない。
三鷹の深大寺と調布の深大寺はまだ自治体が別だからよかった。だが、もし合併したら?
630-8016 奈良県奈良市南新町(みなみしんちょう)(52~212番地)
630-8356 奈良県奈良市南新町(みなみしんまち)(1~32番地)
950-3323 新潟県新潟市北区東栄町(とうえいちょう)
950-3104 新潟県新潟市北区東栄町(ひがしさかえまち)
673-0012 兵庫県明石市和坂(わさか)
673-0012 兵庫県明石市和坂(かにがさか)
住所については、例外の枚挙には暇がないのである。
そして永遠に地名は増殖する。
なんかまだまだまだまだいい足りないが、長くなったのであと2回ぐらいはつづく
参考
とにかく日本の住所のヤバさをもっと知るべきだと思います
https://note.com/inuro/n/n7ec7cf15cf9c
住居表示に関する法律
https://elaws.e-gov.go.jp/document?lawid=337AC0000000119
愛知県海部郡飛島村大字飛島新田字竹之郷ヨタレ南ノ割は本当に日本一長い地名か?
https://dailyportalz.jp/kiji/140708164564
コメントを残す