前回の投稿から4ヶ月ほど下書きのまま保存されているのをみつけた・・・。そうだこの続きも書こうと思ったままになっていた。
教科書が読めない子供たち
前回の投稿の続編。
AI vs. 教科書が読めない子どもたち 新井 紀子著
曰く、教科書を読んでも文意を汲み取ることができない、教科書を読めない子どもたちがかなりいるそうな。なんとその数、約3割。おもえば中学2年の頃、数学の教科書に書かれた「任意」の使い方に納得できず、学校から教科書会社に電話してしまった口なのだが、たぶんそういうガチ中二病が3割とかそういうことではないようだ。
それまで誰も疑問をもっていなかった「誰もが教科書の記述は理解できるはず」という前提に疑問を持ったのです P185
・・・えっと、教科書を読んで素直に頭にはいってしまうエリートさんも問題だとは思うのだが、読んでも意味を汲み取れない人がいることに気がついていなかったということには新鮮な驚きを覚えた。
下手の考えサイコロのほうがまし説
AIには「同義文判定」「推論」「イメージ同定」「具体例同定」がまだ難しいそうだ。
そこで人間について調べたのだそうだが、一部のひとについてはいっそ考えないで答えてもらったほうがましという答えが出てしまった。
図3-8 P214
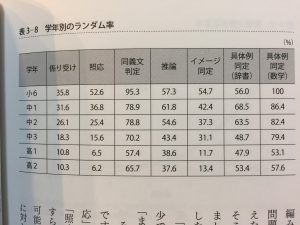
回答選択肢を適当に選んだときよりも、低いスコアを出す受験者数の割合。学年別ランダム率を示した図。
推論や同義文判定など考慮せずに選択肢を選んだほうが得点が高くなる分野がある。逆に、係り受け、照応のランダム率は低く、ディスクレシアなどのなんらかの障害があることが考えられるとのこと。
推論や同義文判定ができなければ、大量のドリルと丸暗記以外、勉強する術がありません。(略)「一を聞いて十を知る」ために必要な最も基盤となる能力が推論なのです。 P215
問題文が読めない
一般にテストは信頼性、妥当性、客観性が求められる。
同じ人が同じような問題でなら何回でも同じ点数が取れるかどうかという信頼性と、用いる評価方法が測定対象となる能力や行動を測定できているかの妥当性、採点者が変わっても結果が同じかどうかの客観性が必要だ。
表3-10 P220
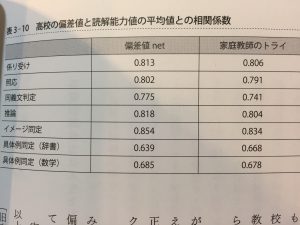
高校の偏差値と読解能力値の平均値と相関係数
ランダム化率の高い推論やイメージ同定での相関係数の高さが注目すべき点。
この相関係数の高さから、同じような能力値のひとが同じような結果を返すテストの信頼性はとかく高そうだ。もしかしたら、学校の入学試験などというのは「数学の能力」などよりも、設問を読めるかという読解能力値に評価妥当性があるのかもしれない。
図3-1
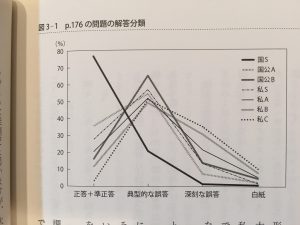
偶数奇数問題の証明の問題正答率である。典型的な誤答が国立S級以外の大学生に異様に多く、逆に言うと、国立S級の大学の子は、この手の問題に適応化、最適化されている子があつめられているとも言える。
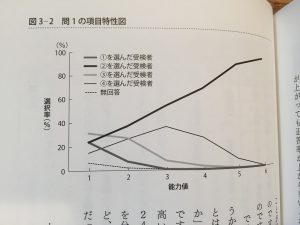
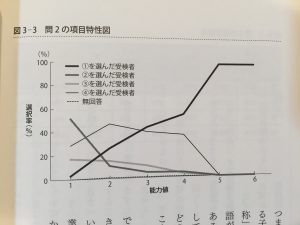
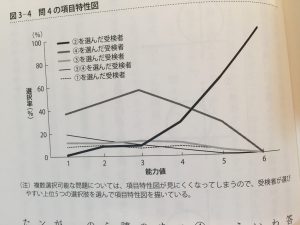
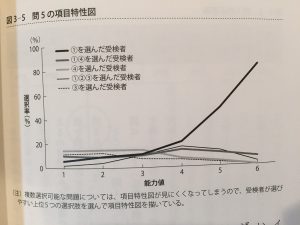
能力値別に誤読させてフィルタできる、綺麗なトラップが作れるようだ。
この綺麗なひっかかりを見ていると、錯視に近い文章読解について脳の認知機能があるような気もする。
聞いたこと無い単語をまぜてスポット的に認知を歪め意識を逸らさせたり、修飾語を離して読者をミスリードさせる方法とか、そういうバッドノウハウが文章問題作成という分野で蓄積された結果なのではないか。
幼児期における発達で、自己と他者は異なるという比較認知やメタ認知力の成長がある。回答者の能力に差があるとすれば出題者の設問意図の斟酌。つまるところ忖度力の差なのかもしれない。
ということは、強いAIが生まれるかどうかは、AIが己と他を認識できるようになり、忖度できるようにならないといけないということだ。
原生生物から進化するために、自己と非自己の認識が必要であったが、AIも進化のためには自己の範囲を認識できるようになる必要がある。
教育環境と遺伝
近代工業化以降は、マニュアルに定めたとおりのオペレーションができるひとを社会に供給するために機能し、評価してきた。日本の教育はそのような点で効果的であったと理解している。
就学補助率と能力値との強い負の相関です。
//
就学補助率が高い学校ほど読解能力値の平均が低いことがわかった
//
貧困は読解能力値にマイナスの影響を与えています。
P227
ここには極めてセンシティブな問題がある。
親の文化資本にアクセスできないからという、環境要因と、そもそも遺伝的に発言しない形質としての認知能力、生物学的要因だ。
「中高生は教科書を読めているか」という事実を考えようとも、調べようとしなかったのでしょうか
//
ビックデータに基づくサイエンスを教育に適用したのです
P239
経験上わかっていても、解決策がなければ蓋をして見なかったことにするのは日本の事なかれ主義では王道だ。サイエンスが教育に適用されたとき、もしかしたらそこに待っているのは現在の社会では差別とされるような区別かもしれない。
遺伝的に長距離走に向いていない筋肉を持つひとや、短距離走に向いていない筋肉を持つ人がいるが、遺伝的配向でそもそも学ぶことができるアクセスを制限されてしまう可能性がある。
エビデンスベースドラーニングは、教育を高効率なものにするかもしれない。しかし、他方でいままで勉強が足りないものとしていた建前も崩してしまうかもしれない。
ITやAIでは代替不能な人材、意味がわかり、フレームに囚われない柔軟性があり、自ら考えて価値を生み出せるような人材
P258
AIに絶対に代替できない仕事の多くは、女性が担っている仕事です。子育ては汎用AIが登場したとしても、最後まで人間がすべき高度知的労働として残ります。
//
男性社会は女性が担っているというだけの理由で、介護や育児やアノテーション設計のような知的な仕事の担い手に対して、十分な地位と対価を支払っていません。
P259
ここでの対価が貨幣経済的なものであるのであれば、それはそのとおりなのかもしれない。東京医科歯科大学の入学試験でのハンデキャップのようにアンフェアな競争下にあるのも事実だ。
しかし、他方でその男性社会が形成するような評価生態系の中にはいりこまず、女性による評価社会があるのも事実。母親としての地位はお金や組織の肩書で交換可能なものではない。代替不能なものである。
AIに代替されないものというのは、そのような代替の脅威にさらされない役割なのだとおもう。
貧困と遺伝子
教育と親世代の年収に強い相関があり、教育格差「やむをえない」が6割を超えるそうだ。
教育格差「当然」「やむをえない」6割超 保護者に調査
https://www.asahi.com/articles/ASL3S5VPYL3SUTIL014.html
交通事故と学歴に相関があることを保険会社がみつけて、保険の掛け金を変更するという現実は半分来ている。統計上の相関は破産や事故に結び付けられて考えられ、保険のような事前に結果の担保をするような仕組みにも影響を与えることだろう。
AIは人間と同じ感覚器を持ちうるや
人間が社会生活のなかで獲得している明文化されることのない暗黙知。これを理解と呼ぶのであれば、その獲得に必要なのは、人間と同じような社会生活である。
つまり、感覚器を有して人間と同じ生活を送ることでしか外部環境、外部情報はセンシングできないので、もし、演算能力や記憶容量が増えたとしても、そこからは人間のようなAIは生まれない。
暗黙知を教師データとして与えるにはデータ化が必要。ディープラーニング以前は、人間による職人的なチューニングが必要で、その過程でどうしても情報密度が落ちる。センシングの部分で人間の生体センサー並みの感覚器を、人間と同じようなタイムラインで保有してストックできるようになれば、AIの暗黙知と人間の暗黙知が揃うことがあるかもしれない。
だが、現段階では計算機はそのような感覚器を持っていないので無理である。味覚センサーも、臭気センサーも、半導体が解決するより先に、生体組織で解決されるかもしれない。視覚器、聴覚器については人間のそれを超える性能が実装されてきている。映像解析や音声解析からAI化が進むのも自然な流れだろう。
個体差としての認知能力
コンテキストが認識ができず、ただひたすら暗記するよりなかったとしたら?
中学生ぐらいで100走でいえば12秒代で、水泳でいえば100メートル自由形で70秒切れるやつとかがいる。走れる人間なら、トレーニングを詰めば10秒代に乗るかもしれないし、60秒も切れるようになるかもしれない。でも9秒を切ることはないだろう。
言語、共感性や、運動能力で人間の能力というのは正規分布に広がる。賢さも同じようなレベルの生体機能でしかない。
生体には限界や加齢もある。
人工頭蓋変形で知能をあげるというような、文化風習があった歴史もあるが、遺伝子操作でもしないかぎりは、人間は生物学的なホモ・サピエンスのくびきの中にいる。しかし、AIは生物学的な制限を受けない。
足の速さの価値が車の経済的価値におきかわったように、同じように代替されるものだとおもう。
AIと人類の比較は、お米とガソリンの比較に似ている。
同じジャポニカ種の、ササニシキとかコシヒカリとか、同じ料理法、似たような風味であるから比較ができるのであって、まったく異なるものとの比較品評に意味があるのかと似たようなものだ。カロリーベースで比較して意味があるか?
思考は外部デバイスにまかせてしまえばよいやという時代がきたら、どれだけ早く入眠できかとか、視力のよさとか、皮膚の感度のよさや、味覚や嗅覚などの外部と接しうる器官の生体性能のような、現代ではおおよそ賢さとは関係ないものが賢さという意味にかわる時代がくるかもしれない。つまりのび太くんこそがAIに代替されない優秀さを持つことになる。