駅前にデータセンターをつくることに反対意見があるようだ。
個人的には駅前データセンターはそんなに悪くない判断だと思う。
なんでかということをつらつら書こうと思う。
人口動態とビルの減価償却年数
一般的な鉄筋コンクリート造の建物の減価償却期間は34年以上が必要であり、耐用年数は肉厚鉄骨で51年、鉄筋コンクリート造で70年となる。
つまり、鉄筋鉄骨のコンクリを建てると、半世紀はそれがそこに残る。
今、戦後高度経済成長期に建てた半世紀前のビル群が償却期間を終え、問題が顕在化してきている。
定借ではなく分譲してしまったために権利関係の整理もできず、住民に退去してもらうこともできず、壊すにも莫大な費用がかかり、かといって経済合理から建て直すこともままならずにっちもさっちもいかない「負」動産の続出が加速する。
壁紙変えましたぐらいのリノベーションで誤魔化して、現地をよく見もしない外国人などに売りつけることで値段が支えられているが、その本質は原野商法と似てる。
新規にビルがどんどん建てられているが、築浅の15~20年ぐらいは、まだいいかもしれないが基本的には減価償却費として計上できるのは減価償却費の計算方法が
「減価償却費 = 取得価額 × 0.9 × 償却率 × 経過年数」
であることからも分かる通り、賃料収益が悪化する築古になってからなので、だいたいの土地持ちや不動産オーナーなどは、騙されてノンリコースローンだとかでモノも取られたうえで借金だけ背負う。
高く買いますよ、ビル建てますよなどと甘言で上モノ壊したら再建築不可のまま都市計画税とか固定資産税が跳ね上がって、泡吹いて駐車場にして収益物件になってさらに税金があがって全部むしられる未来。
まあ本質は老老相続なのでご当人は勝ち逃げなのかもしれないが・・・。
さてさて、話しがそれつつあるので戻すが、今、耐久年数があるビルを建てた場合、目先の利益のために生贄を探さないのであれば、街の人がよくよく考えなければいけないのは築後20年以降の事である。
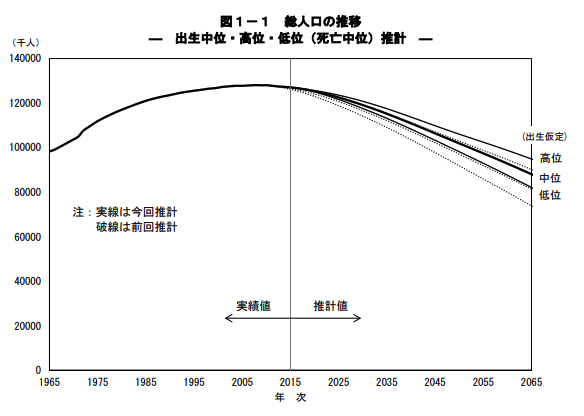
今年生まれるであろう子どもの数は70万人を割りそうだ。15歳以下の人口数は約1500万人。
この1500万人という数字は昭和5年の20~35歳の人口に相当する。
つまり何かってぇと、20年後に住宅を必要とする働き盛りの20~35歳の人口は昭和5年並になる。
日本の市町村のおおかたが村だった時代の需要しかないのに、壊すも治すもできん耐久財を大量に抱えることになることが目に見えている。
20年後、大抵の商用ビルやら住宅用のビルなど、老人ホームか、しいたけ栽培ぐらいにしか使えやしない。
昭和5年にあなたの街に何があったか国土地理院の地理院地図(昭和29年ごろの航空写真がある)でも見てほしい。
千葉ニュータウン中央駅付近に昔なにがあったか?
1961~69年の千葉ニュータウン中央駅付近
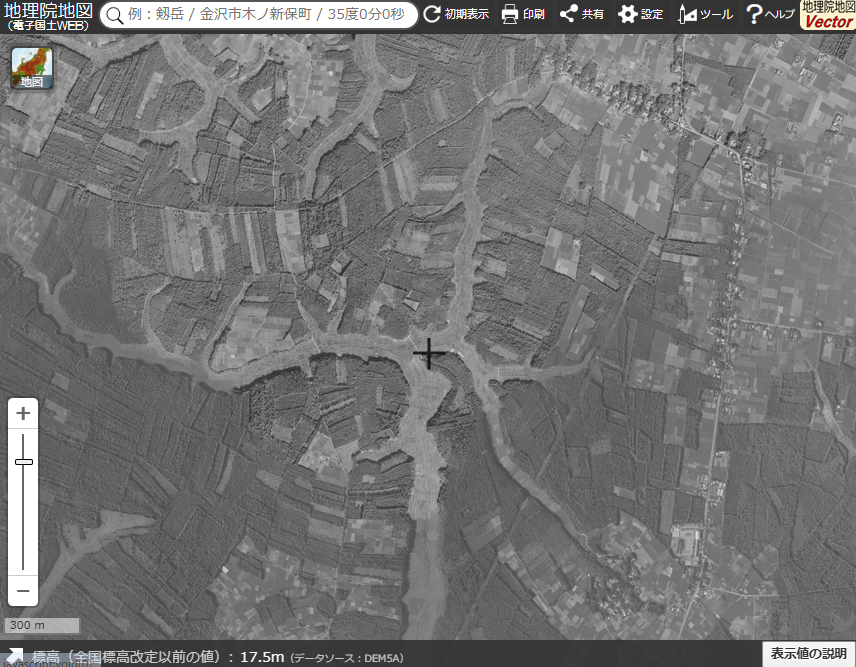
https://maps.gsi.go.jp/#15/35.801595/140.121517/&ls=std%7Cort_1928%7Cort_riku10%7Cort_old10&blend=000&disp=0001&lcd=ort_old10&vs=c1g1j0h0k0l0u0t0z0r0s0m0f1
商業フロンティアとしての駅前
駅前に賑い施設を誘致することは街の活性化には重要。
しかし、時代のみると、商店街からは八百屋、魚屋、豆腐屋、肉屋などの生鮮食料品屋が消え、本屋が消え、だいたいの個人商店は消え去って久しい。これが戻ることはないだろう。
集約化と商品のコモディティ化は逆行しえない。
経済競争において、ロケーション優位は生産地に近いか、あるいは消費地に近いかに依拠する。
駅前商業産業が優位だったのは、人通りが多く消費地に近かったからだ。
徒歩移動だった昔ならこの優位は街道沿いになり、鉄道網ではなく自動車社会の場合は幹線道路沿いとなる。
はてさて、半世紀後に駅前は消費地最前線であろうか?
自動運転、配送ドローン、パーソナルモビリティが発達した未来でも?
日本で最初の鉄道ができたのは明治5年(1872年)のことだそうだ。
駅ができて100年を過ぎている街はそう多くない。
果たして50年後もそこに駅が必要とされているだろうか?
飛行機とかになってない?
縦方向に集積しているところはビル風があるので、高さ制限があるビルの無いエリアのほうが裏返って人通りのある駅前になる可能性まである。
前段で述べたように耐久財はそう簡単にはなくすことはできない。
人々が都市部で鉄道網を利用していたのは通学通勤の為だ。
人が集積するといいという経済合理のためだ。
付加価値生産において人力の労務の時代に巻き戻らないことは、現在の産業分類別の付加価値生産額を見ても明らかだと思う。
人がいなくなる未来、経済のフロンティアは演算力を生み出すデータセンターが生産地であり、あるいは電力を消費する最終消費地となるかもしれない。
データセンターの特性と地域レジリエンス
レジリエンスってのは柔靭性、弾性とか回復って意味。
地域力つったって、そんなものは見えはしない。
では、地域レジリエンスはどのように類推することができるだろうか?
樹齢のいった御神木がある神社の周りは地価が高いみたいな話しがある。
神秘性とか信心ということではなく、数百年と樹齢を重ねられたということは、大規模な災害、浸水水害、地盤が強いことの証左になっているからだ。まあ、あと古樹大樹って、地域住民の助けなしには維持管理できないからね。病気やら虫に食われたり、よさげな木があるで、薪にされて終わりよ。
これと同じぐらいわかりやすい指標にデータセンターが入ってきた。
データセンターというのは、地盤が強固で地震加速度による被害が軽微で、水害による浸水が想定されておらず、かつ電気系統が複数はいってくるようなところに作られることが多い。
さほど距離が離れていなくても地震で揺れるところと揺れないところがある。
これは地べたの下の堆積物の違いによる。プリンのような泥炭層にのっているのか、岩盤の上にのっているのかで当然上の建物が受ける加速度は変わる。
精密機械の塊でものすごく高いデータセンターを、プリンの上で保管するわけにも、水没するかもしれないところや、土に埋もれるような場所においておくわけにはいかないので、どこに建てるかは非常に重要な戦略性をもった選定がおこなわれる。
族が攻め込んできたり、暴動がおきるような治安の悪いところにも置いておけない。
千葉の印西市は、米国側の海底ケーブルの引上げ地(多分2系統?)が合流するところあたりで、東京につなぐハブになっている。結構な投資をしたとも聞いている。
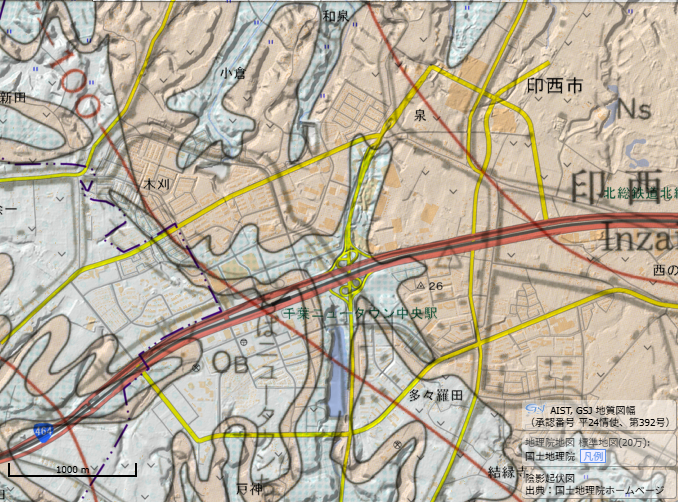
産総研の陰影起伏図に特殊地質図を合成表示したもの。
https://gbank.gsj.jp/geonavi/geonavi.php#14,35.80856,140.12129
まあ、反対する人たちは、反対することがしのぎで、将来のこととか関係ないのかもしれんけどね。
参考
駅前の一等地にデータセンター計画、「人が入れない施設が建っていいのか」と反対の声相次ぐ
https://www.yomiuri.co.jp/national/20250425-OYT1T50156/
「減価償却費」の計算について
https://www.nta.go.jp/taxes/shiraberu/saigai/h30/0018008-045/05.htm