NHKがまとめページにて変更後と変更前PDFを公開した。
https://www3.nhk.or.jp/news/special/moritomo_kakikae/
北朝鮮関連とか、まとめページをつくってくれるようになった。NHKのWEBの中の人がんばってるよね。
さて、森友関係については、いろいろ言いたいこともあるのだけど、まあ、いろいろな部分はおいておいて、無駄な労力をかける人たちが出る前に、ああ、既に一日経過しているので時遅しかもしれないけれども、変更前と変更後の文章の比較をおこなう方法を案内しておいたほうがよいように感じた。
画像やPDFのテキスト化
EvernoteやgoogleDriveを使えば自動でOCRしてくれるようになった。いい時代である。
電子データを印刷して、わざわざ汚れたスキャナで取り込んで作ったようなデータでも、再電子テキスト化してくれるのである。
やり方は簡単、ぶっこんで、開くだけである。一応やり方を書いておく。
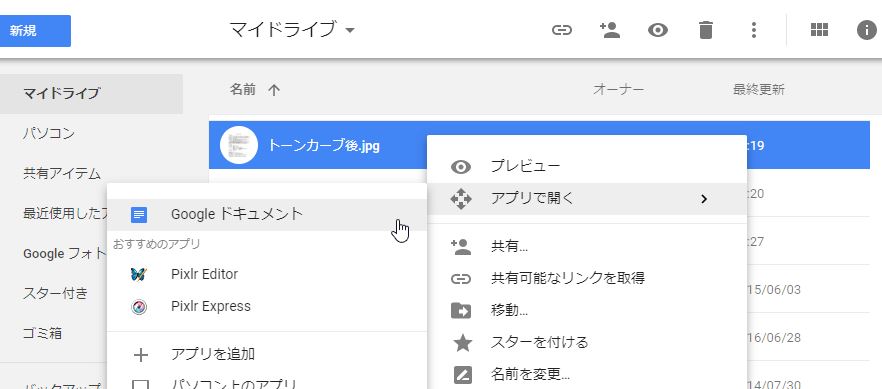
アップロードして右クリック、Googleドキュメントで開く。以上だ。
こんな感じに上に画像。下にテキストが出る。

くそ汚れた画像のテキスト化
今回のような2ページ印刷されてたり、変なところに変な記号がはいっていたりすると、文字認識アルゴリズムがうまく動かないので、ページのスクリーンショットをとって画像にしてからOCRをかけることにする
スクショは別に何使ってもいいけれども、winの場合はGreen shotをつかっているので一応案内しておく。
http://www.vector.co.jp/soft/winnt/art/se505369.html
問題文書。いきなり1つ目の文章がくそ汚い。
汚すぎるのでPDFを拡大してから画像化する。

ここまで汚れていると流出経路を特定するために、わざと汚しているのかもしれないけれども、酷いね。省庁って、もしかして、わら半紙にガリ版刷りなのかなと思う程度に酷い。
ここまで汚いのは流石のgoogleさんも想定していないので、手前で画像的な加工が必要である。こういう汚れのときは画像編集ソフトでトーンカーブをつかおう。photoshopを使ってもいいが、うちみたいな貧乏人は無料のGIMPというフリーの画像編集ソフトもあるのでそれで案内する。photoshopでも編集方法は一緒ね。
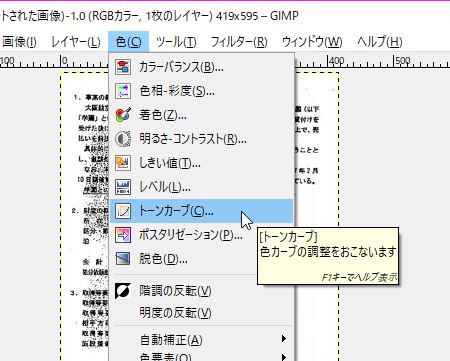
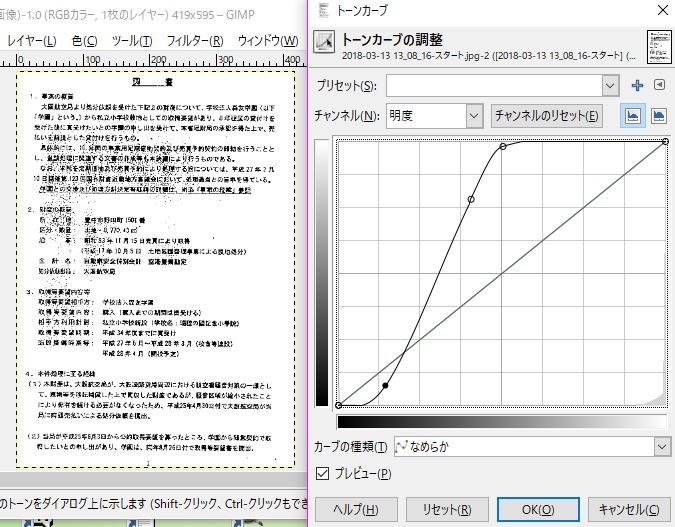
こういう汚れ系はトーンカーブを右上を上に、左下を下にすれば結構落とすことができる。線画とかからデジタル化したいときにつこーたらいいよ。ただ、今回みたいに文字の濃さと同じぐらい汚いと無理だね。ほんとなんだろうFAX?
でも、ま、ひと手間でこれくらいにはなる。

ちっとも読み取れなかったのが、まああとは文章修正ぐらいでなんとかなる程度には読み取れるようにはなった。
変更部分比較
あとはテキスト化した文章を比較すればいい。diffとかcompareって呼ばれる機能。んー。atomのコンペアのプラグイン入れてとかいうのは説明するのがしんどいので、懐かしのDFとかでどうだろう。
https://www.vector.co.jp/soft/win95/util/se113286.html
変更されている行を色違いで出力してくれる。
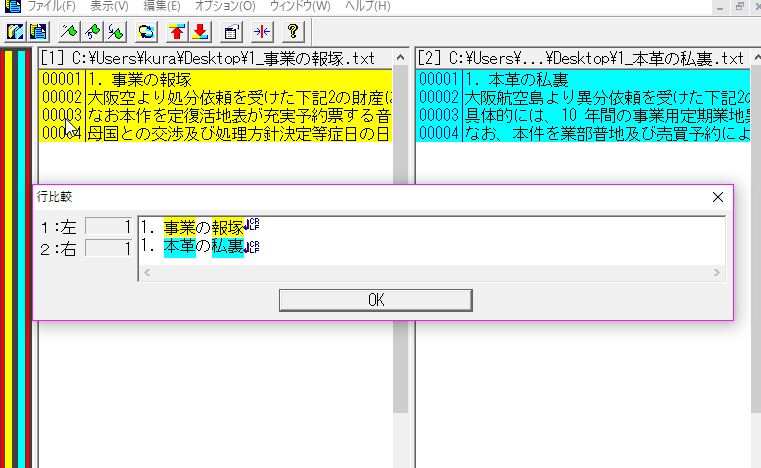
・・・。これじゃわかり難い?
wordの変更履歴
まあこんな事をしなくても、文章を作成した元の電子ファイルが残ってりゃ、変更履歴ボタンを押されていれば、いつ誰がどこを更新したかなんて残っているんだけどね。eガバメントってなんじゃったんだろうね。
コード管理システム
誰かがgithubにあげればいいじゃないと言っていたが、githubのようなコード管理システムをつかえば、今回のような誰が、いつ、なにを改変したんだかわからないようなことで混迷することもなかっただろう。プログラムはコードと呼ばれるが、法律もコードと呼ばれる。公文書はなんだかわからないけど。人間の法律はコンパイル通りそうもないよね。
震災直後、写真に写り込んだ避難所の名簿を文字起こしするとかいう、ソーシャルな働きは価値があったと思う。今回も、PDFで公開された情報をgithubで市民団体とかが、登録したりして可読性を高めるとかいう動きはあってもいいかもしれない、が、そもそもが、無駄なことだと考えると残念でしかない。オープンデータとして提供されていれば、とか、もっといろいろできることもあろうに残念だ。
ドイツ連邦の法律がGitHubで管理されるようになったってお話しは、もうずいぶんと昔のニュースであったように思う。gitとかで管理されていれば履歴を追うことも、どこが変更されているかも、誰が変更したかも追うことができる。
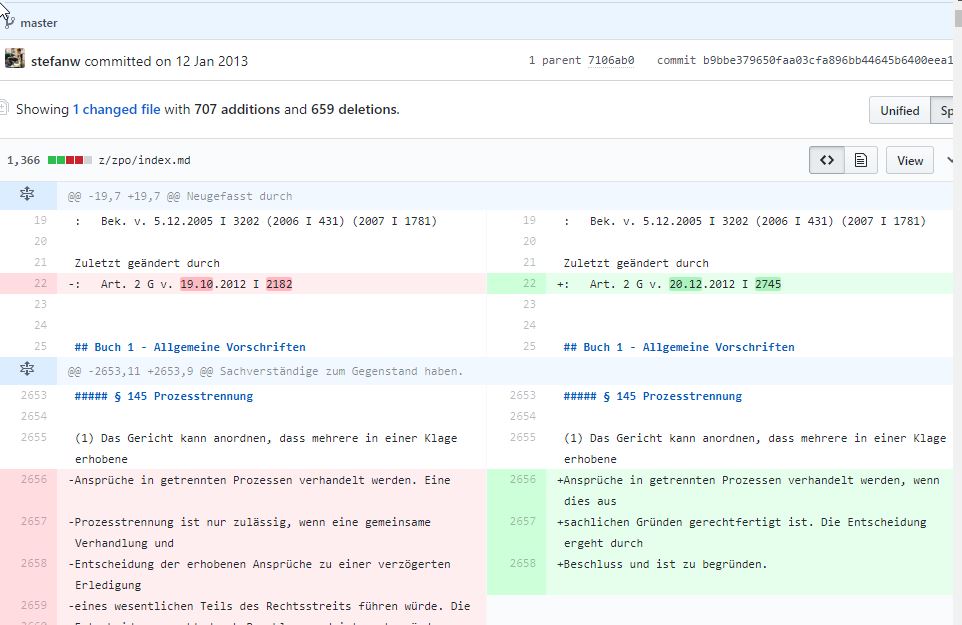
https://github.com/bundestag/gesetze
右上のコミットログに表示されるように文章のフィンガープリント(指紋の意味ね)もあるので、誰かが悪意をもって差し替えるには、ちと困難なようになっている。文章の内容をシードにMD5などで暗号化(ハッシュ化)をおこなった結果なので、内容を書き換えると結果の暗号化も変わってしまうわけだ。
これらの暗号は文章を種に生成した不可逆なもので、暗号を複号しても文章にはできないが、同じ文章からは同じ暗号ができあがる。ま、言ってみれば、ある文章を15文字おきに拾い読みしたら同じ文章からは同じ文字列ができあがるよねみたいなもの。するってぇと、つまり、内容を秘匿にしたままフィンガープリントだけは公開しても、いいよねっていう運用ができる。
ちなみにこのようなテクノロジーは15~6年も昔からある技術である。ハッシュ値をさらにシードにしてチェーン化すれば、内容の連続性担保できるし、さらにそれを公開台帳に記しておけばいいんじゃねというブロックチェーン技術は、こういうところに根ざしている。ブロックチェーンだって技術的には7~8年ぐらい前のお話しだ。
話しがそれた。
で、今の技術で何ができるか。
電子化して誰かがつくった書類をわざわざ印刷して、押印して、さらに電子化するとかいうお役所仕事がなされている。で、なにかがおきたときにはどこにあるんだかわからないとか、俺の原本は108種類あるぞ!的なことがなされるわけだし、検証も労力がかかって無駄である。無駄である。無駄である。無駄である。無駄無駄無駄ァァアアァァアアアア!
無用の用と呼ぶには、あまりにも。やらなくてもいい仕事をやって仕事を増やす。よくないよね。
誰かの仕事がヘリますように。
コメントを残す